





11-数据结构-1
数据结构-1
并查集
普通并查集
class UnionFind {public: vector<int> f; vector<int> sz; int cc;
UnionFind(int n) : f(n), sz(n), cc(n) { iota(f.begin(), f.end(), 0); }
int find(int x) { if (f[x] != x) f[x] = find(f[x]); return f[x]; }
bool merge(int from, int to) { int x = find(from), y = find(to); if (x == y) return 0; f[x] = y; sz[y] += sz[x]; --cc; return 1; }};带权并查集
//TODO普通Trie树
int son[N][26], cnt[N], idx = 0;
void insert(char *str) { int p = 0; for (int i = 0; str[i]; ++i) { int e = str[i] - 'a'; if (!son[p][e]) son[p][e] = ++idx; p = son[p][e]; } ++cnt[p];}
int search(char *str) { int p = 0; for (int i = 0; str[i]; ++i) { int e = str[i] - 'a'; if (!son[p][e]) return 0; p = son[p][e]; }
return cnt[p];}0-1 Trie树
class Trie {public: static const int MAXN = 1e4; int tr[MAXN][2]; int ptr = 0;
void insert(int x) { int p = 0; for (int i = 31; i >= 0; --i) { bool c = x >> i & 1; if (!tr[p][c]) tr[p][c] = ++ptr; p = tr[p][c]; } }
int find(int x) { int p = 0, ans = 0; for (int i = 31; i >= 0; --i) { bool c = x >> i & 1; bool b = !c; if (tr[p][b]) { ans |= 1 << i; p = son[p][b]; } else { p = son[p][c]; } } return ans; }};线段树
是个完全二叉树,只适用于聚合函数,例如
其中a,b为区间
普通线段树
原数组0-base,tree 1- base
取中点为左
设数组元素数量为,树最后一层数量要满足,需要的结点个数需要满足,由于1-base完全二叉树有多少结点开多大数组,则取上界开大小的数组,实际再+1书写方便
class SegmentTree { int n; vector<int> tr;
// 区间业务 int merge_val(int a, int b) const { return max(a, b); }
// 维护结点 void maintain(int node) { tr[node] = merge_val(tr[node * 2], tr[node * 2 + 1]); }
// 建树 void build(int node, int l, int r, const vector<int>& a) { if (l == r) { tr[node] = a[l]; return; }
int m = l + r >> 1; build(node * 2, l, m, a); build(node * 2 + 1, m + 1, r, a); maintain(node); }
// 单点更新 void update(int node, int l, int r, int i, int val) { if (l == r) { tr[node] = merge_val(tr[node], val); return; }
int m = l + r >> 1; if (i <= m) { update(node * 2, l, m, i, val); } else { update(node * 2 + 1, m + 1, r, i, val); } maintain(node); }
// 区间查询 int query(int node, int l, int r, int ql, int qr) const { if (ql <= l && r <= qr) { return tr[node]; }
int m = l + r >> 1; if (qr <= m) { return query(node * 2, l, m, ql, qr); } if (ql > m) { return query(node * 2 + 1, m + 1, r, ql, qr); } int l_res = query(node * 2, l, m, ql, qr); int r_res = query(node * 2 + 1, m + 1, r, ql, qr); return merge_val(l_res, r_res); }
// 查找查找区间最左边的某值 int find(int node, int l, int r, int ql, int qr, int val) const { if (ql > r || qr < l) return -1; // if (业务剪枝) return -1; if (l == r && tr[node] == val) return l;
int m = l + r >> 1; int l_res = find(node * 2, l, m, ql, qr, val); if (l_res != -1) return l_res; return find(node * 2 + 1, m + 1, r, ql, qr, val); }
public:
SegmentTree(const vector<int>& a) : n(a.size()), tr(2 << bit_width(n - 1)) { build(1, 0, n - 1, a); }
void update(int i, int val) { update(1, 0, n - 1, i, val); }
int query(int ql, int qr) { return query(1, 0, n - 1, ql, qr); }
int find(int ql, int qr, int val) const { return find(1, 0, n - 1, ql, qr, val); }};懒线段树
//TODO持久化线段树
//TODO树状数组
用于动态前缀和,+lowbit是往父结点移动,父结点范围包含指定结点范围,故最后需要一直往上到最后,-lowbit是往兄弟结点移动,兄弟结点互不相交,同时可以跨层,把[0,i]拆成了二进制
class FenwickTree {public: int n; vector<int> tree;
FenwickTree(const vector<int>& a) : n((int)a.size() - 1) { tree = a; for (int i = 1; i <= n; ++i) { // 更新父结点的值 int j = i + (i & -i); if (j <= n) tree[j] += tree[i]; } }
// 前缀和 int presum(int i) { int s = 0; while (i > 0) { s += tree[i]; i &= i - 1; } return s; }
// 单点更新 void update(int i, int delta) { while (i <= n) { tree[i] += delta; i += i & -i; } }
// 区间和 int query(int l, int r) { return presum(r) - presum(l - 1); }};前缀和
对于
可考虑用前缀和优化
因为固定右端 j 时,前面所有贡献都是:
应用场景
统计满足顺序关系的二元组、三元组、四元组
i < j且满足某种值关系- 枚举中间点或右端点
- 每个点贡献来自“前面多少种选法”乘“当前能接多少种选法”
莫队
n为数组长度,m为问题长度,S为块大小,询问区间[l, r]
普通实现
莫队对离线询问进行预处理,从左到右左端点l在同一块的放一起,然后再根据右端点r进行排序(同一块的询问右端点r的位置是任意的)
要理解莫队,要把左右指针分开,要每个询问或每个分块来看,在同一块内,在左右指针移动到指定询问区间的时候,右指针大约最多移动n次,有块,所以右指针最多移动次;对于每次询问,左指针大约最多移动S次,左指针最多移动mS次,由于排序把同一块的询问都分一起了,所以右指针移动次数和m无关,只和块数有关。故普通莫队的时间复杂度为,由基本不等式可知,当块大小取时时间复杂度最优。询问遍历到跨块的时候,如果不做奇偶优化右指针会大量回弹,故让奇数块和偶数块的右指针排序方向是相反的则可以减少右指针移动次数
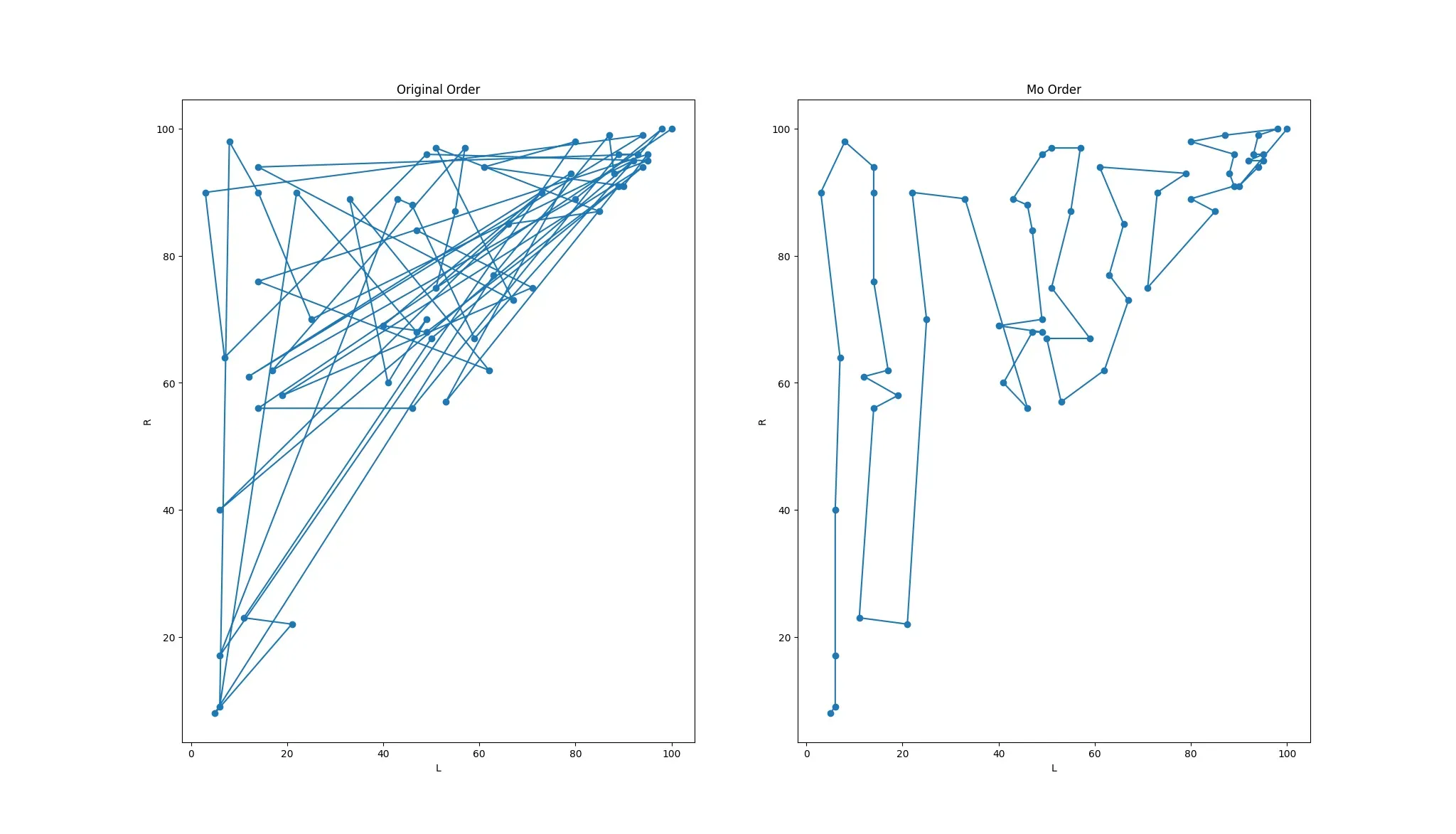
具体移动过程细节参照普通莫队算法 - OI Wiki
莫队区间的移动过程,就相当于加入了 的元素,并删除了 的元素。因此:
- 对于 的情况, 的元素相当于被加入了一次又被删除了一次, 的元素被加入一次, 的元素没有被加入。这个区间是合法区间。
- 对于 的情况, 的元素相当于被加入了一次又被删除了一次, 的元素没有被加入。这时这个区间表示空区间。
- 对于 的情况,(这个区间非空)的元素被删除了一次但没有被加入,因此这个元素被加入的次数是负数。
因此,如果某时刻出现 的情况,那么会存在一个元素,它的加入次数是负数。这在某些题目会出现问题,例如我们如果用一个
set维护区间中的所有数,就会出现「需要删除set中不存在的元素」的问题。代码中的四个
while循环一共有 种排列顺序。不妨设第一个循环用于操作左端点,就有以下 种排列(另外 种是对称的)。下表列出了这 种写法的正确性,还给出了错误写法的反例。
循环顺序 正确性 反例或注释 l--,l++,r--,r++错误 l--,l++,r++,r--错误 l--,r--,l++,r++错误 l--,r--,r++,l++正确 证明较繁琐 l--,r++,l++,r--正确 l--,r++,r--,l++正确 l++,l--,r--,r++错误 l++,l--,r++,r--错误 l++,r++,l--,r--错误 l++,r++,r--,l--错误 l++,r--,l--,r++错误 l++,r--,r++,l--错误 全部 种排列中只有 种是正确的,其中有 种的证明较繁琐,这里只给出其中 种的证明。
这 种正确写法的共同特点是,前两步先扩大区间(
l--或r++),后两步再缩小区间(l++或r--)。这样写,前两步是扩大区间,可以保持 ;执行完前两步后, 一定成立,再执行后两步只会把区间缩小到 ,依然有 ,因此这样写是正确的。
文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!